Which Nvidia Product Should I Use To Optimize And Deploy Models For Inference
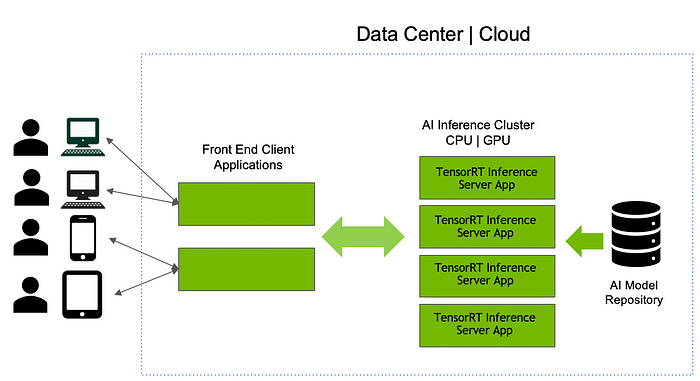
Easily Deploy Deep Learning Models In Production

Tensorrt 3 Faster Tensorflow Inference And Volta Support Nvidia Developer Blog
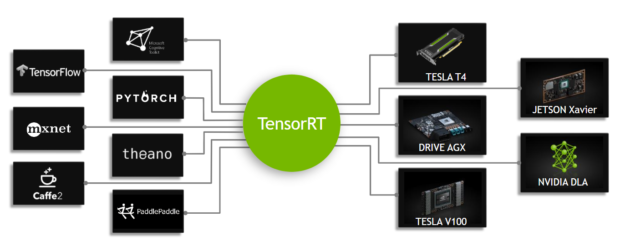
Speeding Up Deep Learning Inference Using Tensorflow Onnx And Tensorrt Nvidia Developer Blog

Nvidia Tensorrt Is A High Performance Neural Network Inference Engine For Production Deployment Of Deep Learning Applications Deep Learning Nvidia Inference
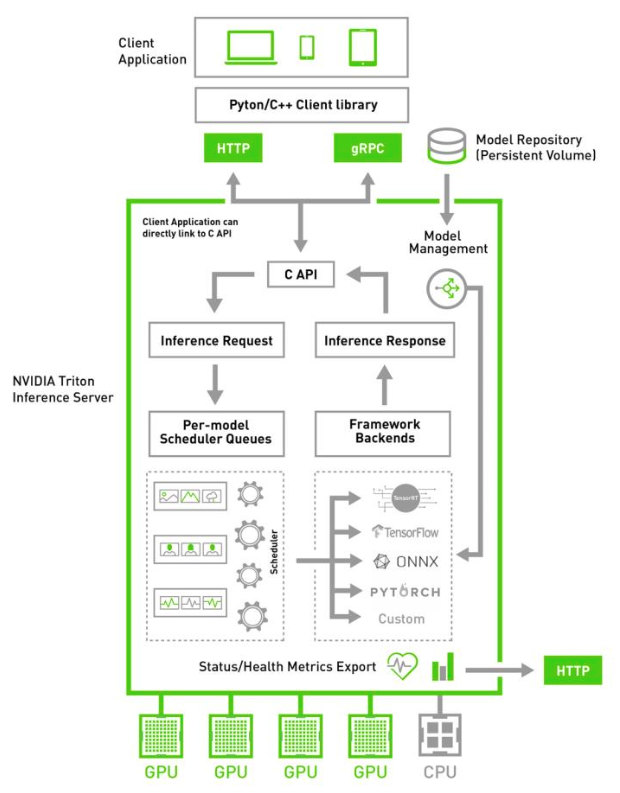
Simplifying Ai Inference With Nvidia Triton Inference Server From Nvidia Ngc Nvidia Developer Blog
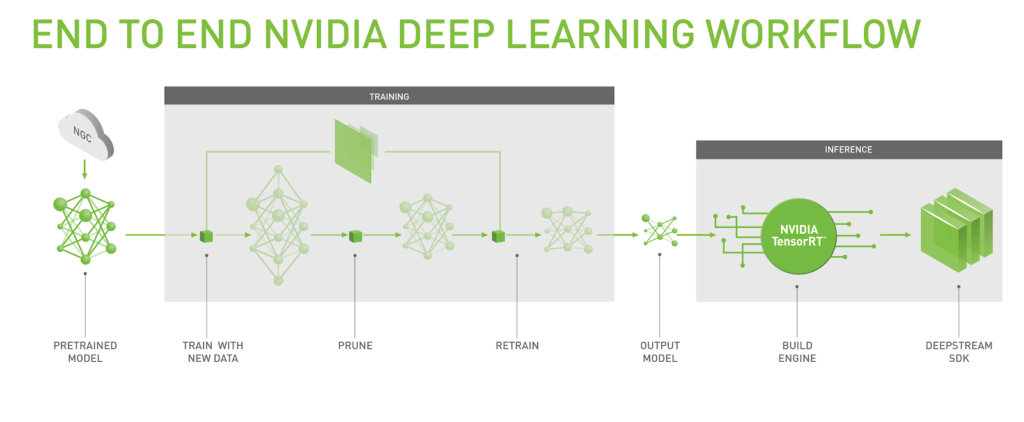
Accelerating Intelligent Video Analytics With Transfer Learning Toolkit Nvidia Developer Blog

Power efficiency and speed of response are two key metrics for deployed deep learning applications because they directly affect the user experience and the cost of the service provided.
Which nvidia product should i use to optimize and deploy models for inference. This level of performance in the data center is critical for training and validating the neural networks that will run in the car at the massive scale necessary for widespread deployment. In this extracted folder we can find the following files. The new nvidia tensorrt inference server is a containerized microservice for performing gpu accelerated inference on trained ai models in the data center. Then we use tensorflow object detection api to export the model.
The new nvidia a100 gpu based on the nvidia ampere architecture also rose above the competition outperforming cpus by up to 237x in data center inference. Those models can be built on any frameworks of choice tensorflow tensorrt pytorch onnx or a custom framework and saved on a local or cloud storage on any cpu or gpu powered system running on premises in the cloud or at the edge. Model ckpt contain the pre trained model variables saved model folder contains the tensorflow savedmodel files. Pipeline config contains the configuration use to generate the model.
Nvidia gpu inference engine gie is a high performance deep learning inference solution for production environments. It maximizes gpu utilization by supporting multiple models and frameworks single and multiple gpus and batching of incoming requests. The systems are tested on workloads that comprise of deep learning dl training ai inference data science algorithms intelligent video analytics iva and security as well as network and storage offload on both single node and cluster based systems. Frozen inference graph pb is the frozen inference graph for arbitrary image and batch size.
An nvidia certified system can run modern workloads including data analytics ai training and inference professional visualization and more.

Nvidia Clara Guardian Nvidia Developer

New Deep Learning Software Release Nvidia Tensorrt 5 Exxact
Abs4vsq2xua42m

Tensorflow Serving Tensorrt Inference Server Triton Multi Model Server Mxnet In 2020 Inference Software Deployment Application Android
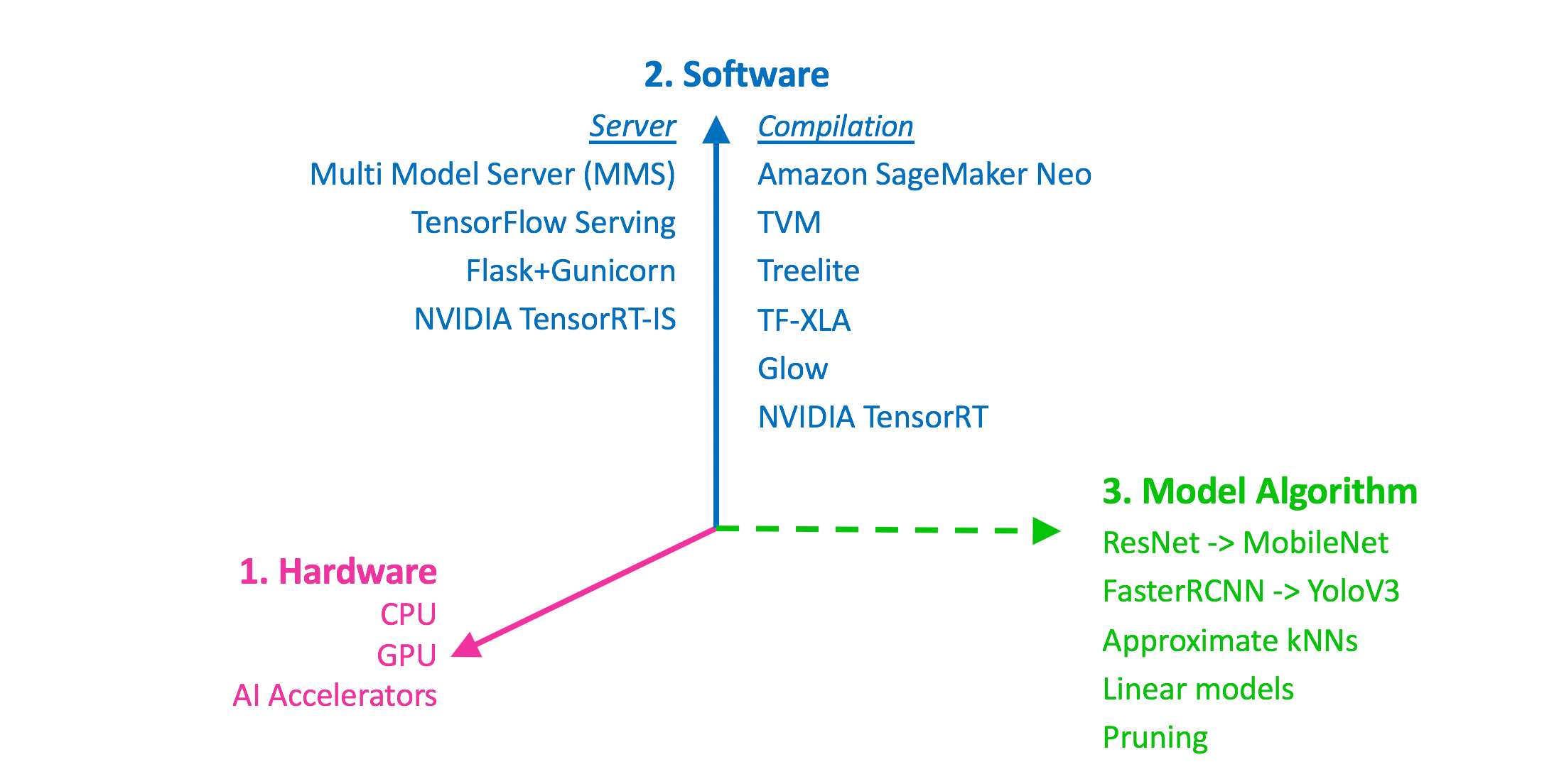
Faster Cheaper Leaner Improving Real Time Ml Inference Using Apache Mxnet By Olivier Cruchant Apache Mxnet Medium
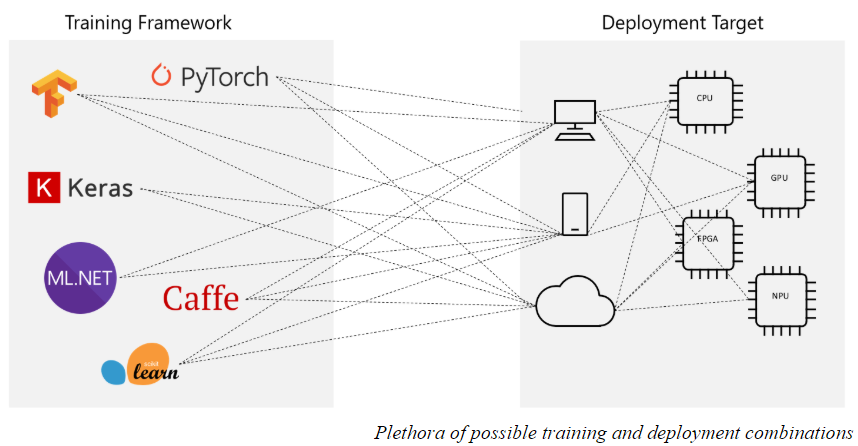
Interoperable Ai High Performance Inferencing Of Ml And Dnn Models Using Open Source Tools By Odsc Open Data Science Medium

Dell Emc And Nvidia Expand Collaboration To Deliver Flexible Deployment Options For Artificial Intelligence Use Cases Dell Emc Deep Learning Use Case Nvidia
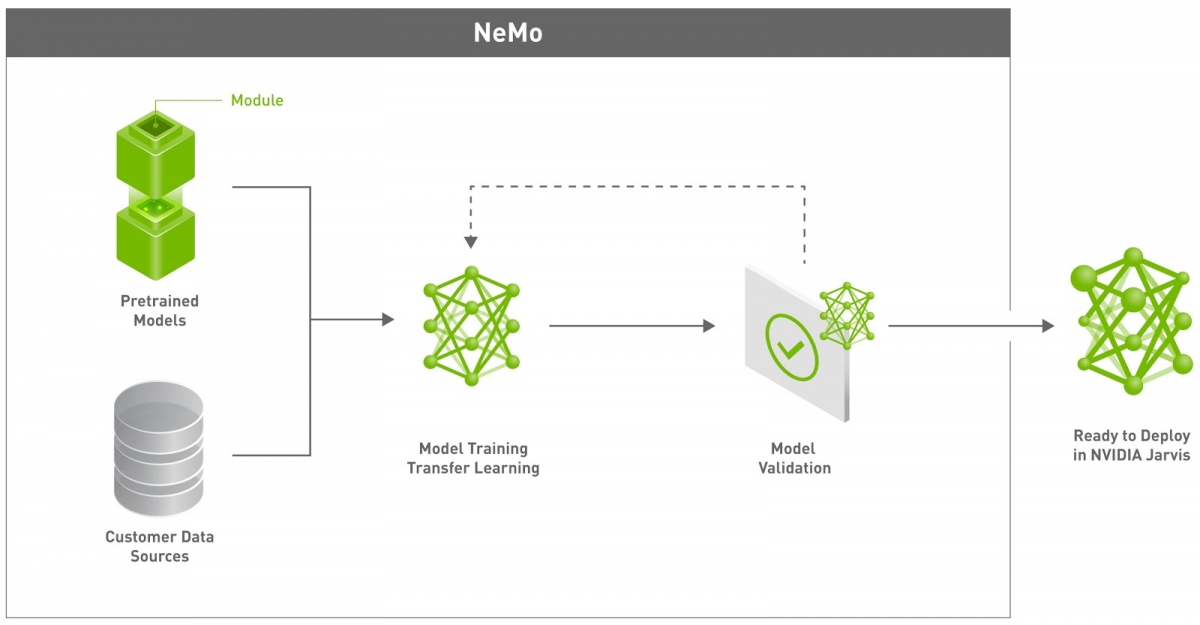
Deep Learning Software Nvidia Developer
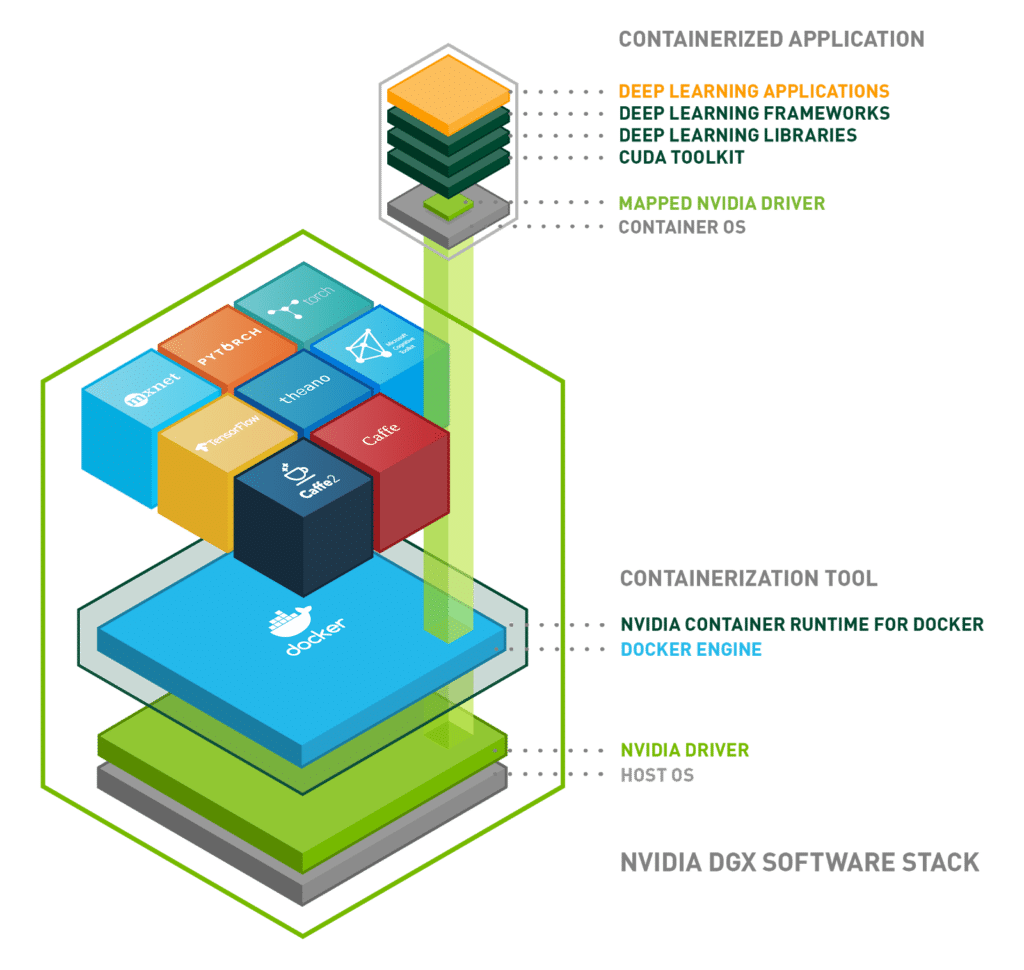
Building A Scaleable Deep Learning Serving Environment For Keras Models Using Nvidia Tensorrt Server And Google Cloud Statworx

Pin On Technology Group Board
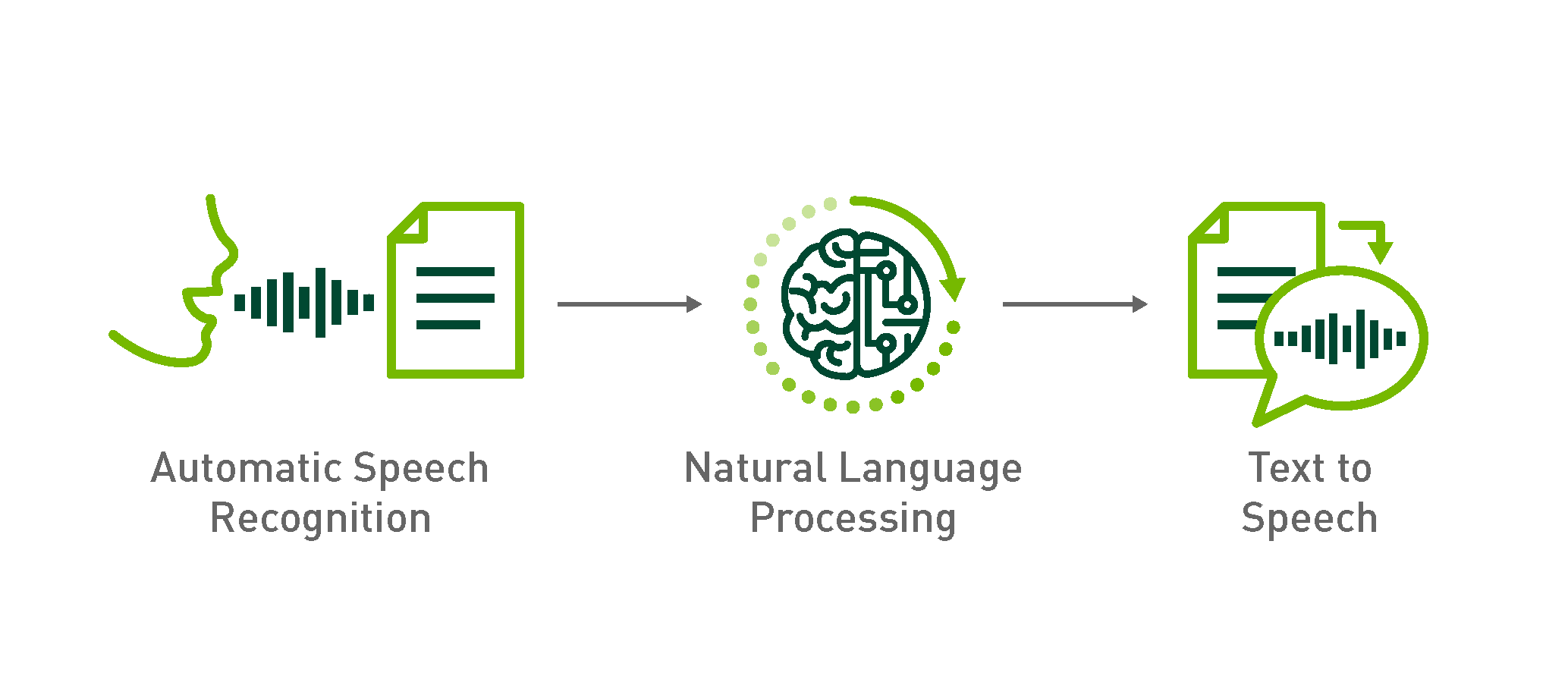
How To Build Domain Specific Automatic Speech Recognition Models On Gpus Nvidia Developer Blog

Accelerated Model Training And Ai Assisted Annotation Of Medical Images With The Nvidia Clara Train Application Development Framework On Aws Containers
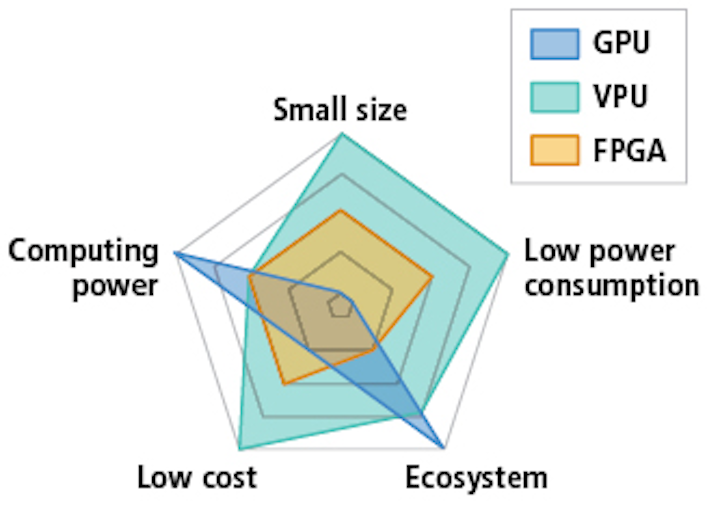
Finding The Optimal Hardware For Deep Learning Inference In Machine Vision Vision Systems Design


