Nvidia Xavier Benchmark
Machine Inference Performance What S It For Investigating Nvidia S Jetson Agx A Look At Xavier And Its Carmel Cores
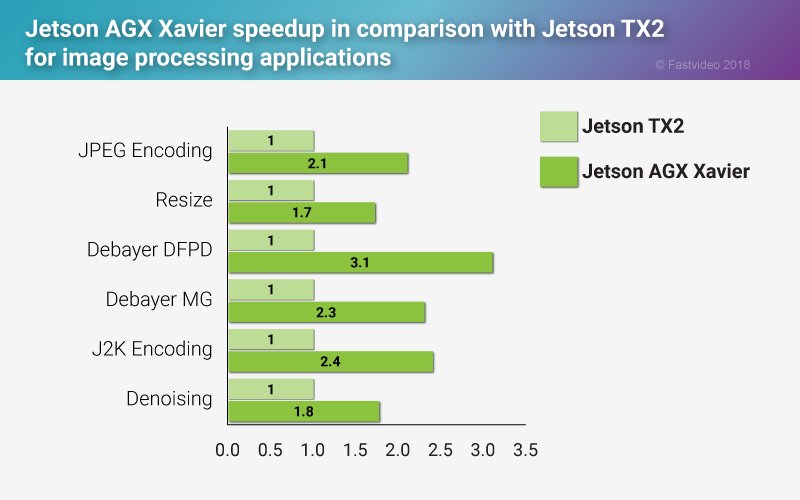
Jetson Tx2 Vs Xavier Performance Speedup Fastcompression Com

Nvidia Wins Mlperf Inference Benchmarks Nvidia Developer News Center

Benchmarks For Jetson Nano Tx1 Tx2 And Agx Xavier By Fyodor Serzhenko Medium

Mlperf Inference Benchmarks Show Nvidia Strength Company Expands Jetson Ai Edge Offerings
Compare Nvidia Jetson Xavier Nx With Jetson Tx2 Developer Kits Latest Open Tech From Seeed Studio
Following that are a variety of cpu only arm linux benchmarks just for seeing how these nvidia carmel cores compare to the arm cpu performance on other socs lower cost developer boards.
Nvidia xavier benchmark. Nvidia has released a series of jetson hardware modules for embedded applications. Nvidia turing gpus and our xavier system on a chip posted leadership results in mlperf inference 0 5 the first independent benchmarks for ai inference. With the nvidia jetson agx xavier developer kit you can easily create and deploy end to end ai robotics applications for manufacturing delivery retail smart cities and more. Jetson xavier nx delivers up to 21 tops making it ideal for high performance compute and ai in embedded and edge systems.
Max n mode for jetson agx xavier. Nvidia xavier extended its performance leadership demonstrated in the first ai inference tests held last year while supporting all new use cases added for energy efficient edge compute soc. Inferencing for intelligent vehicles is a full stack problem. Supported by nvidia jetpack and deepstream sdks as well as cuda cudnn and tensorrt software libraries the kit provides all the tools you need to get started right away.
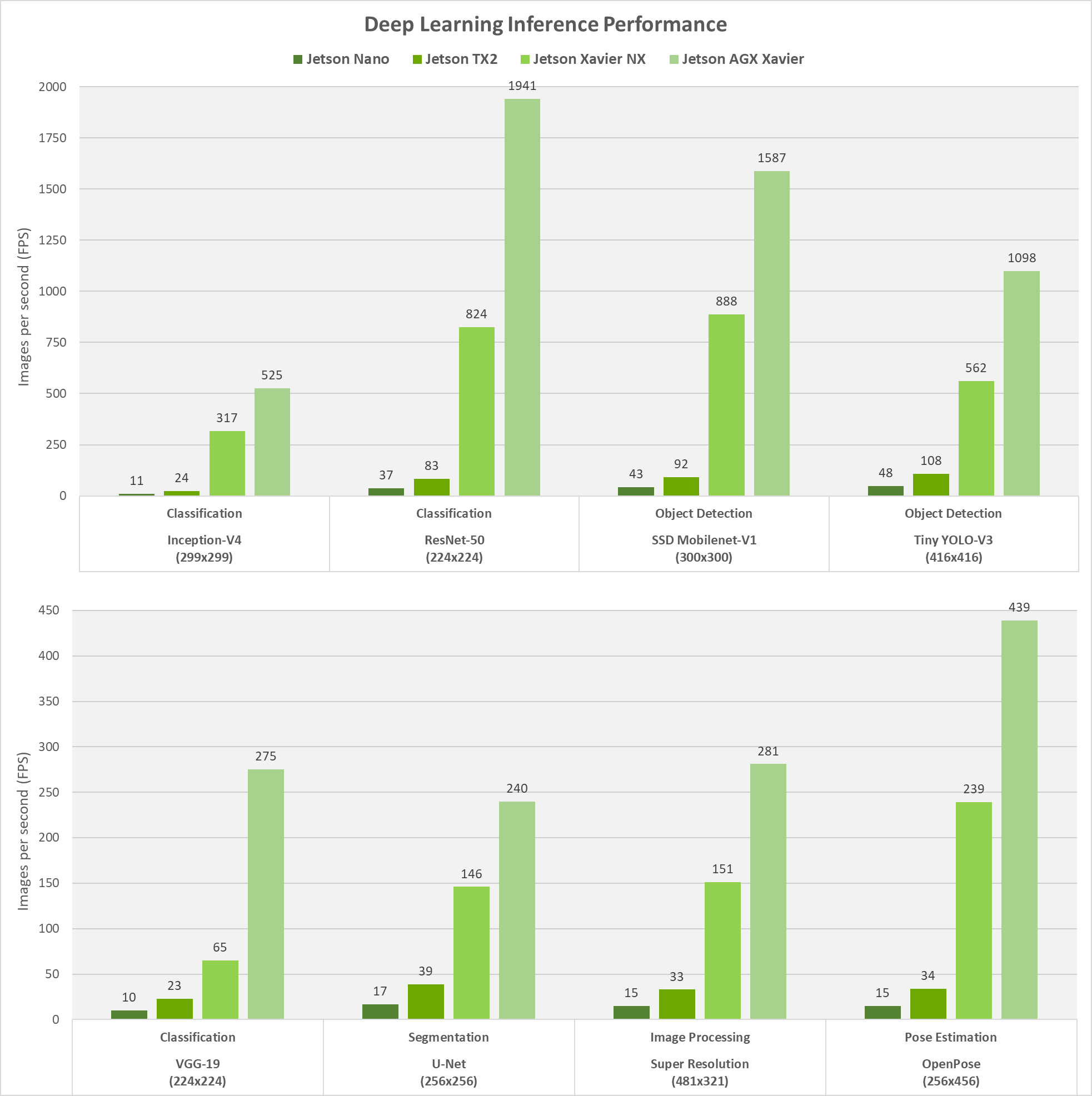
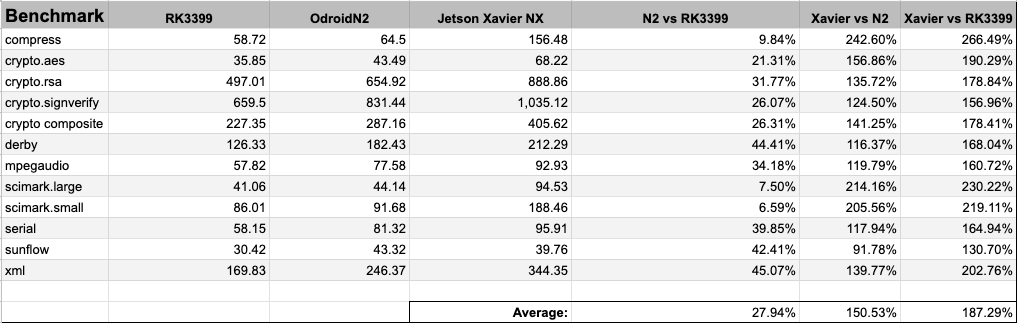
Input image resolution. The nvidia xavier nx is 150 faster than the amlogic and 187 faster than the. On jetson xavier nx and jetson agx xavier both nvidia deep learning accelerator nvdla engines and the gpu were run simultaneously with int8 precision while on jetson nano and jetson tx2 the gpu was run with fp16 precision. Before today the industry was hungry for objective metrics on inference because its expected to be the largest and most competitive slice of the ai market.
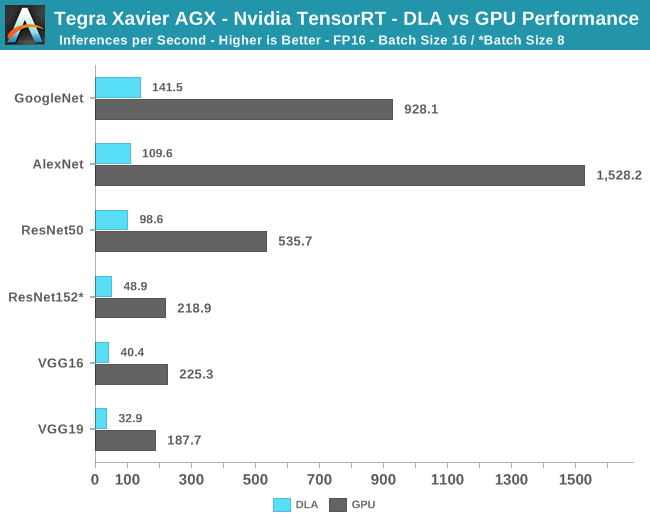
For this round of nvidia agx xavier benchmarking is a look at the tensorrt inference performance with vgg16 alexnet resnet50 googlenet at int8 and fp16 with a variety of batch sizes. Benchmark comparison for jetson nano tx1 tx2 and agx xavier. Nvidia jetson is the world s leading embedded platform for image processing and dl ai tasks. You get the performance of 384 nvidia cuda cores 48 tensor cores 6 carmel arm cpus and two nvidia deep learning accelerators nvdla engines.
Each jetson module was run with maximum performance.
Nvidia Jetson Xavier Nx Benchmarks By Carlos Eduardo Medium
Nvidia Gpus Drive Agx That Leads Mlperf Auto Connected Car News

Nvidia Jetson Nano And Jetson Xavier Nx Comparison Specifications Benchmarking Container Demos And Custom Model Inference Latest Open Tech From Seeed Studio
Deep Learning Inference Benchmarking Instructions Jetson Nano Nvidia Developer Forums

Nvidia Announces Jetson Xavier Nx World S Smallest Supercomputer For Ai At The Edge Tech Coffee House Latest Singapore Tech News And Reviews
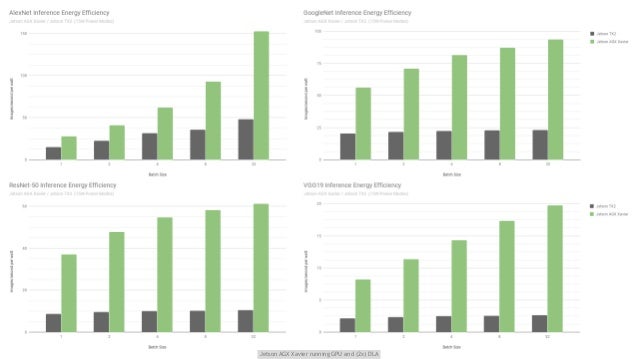
Jetson Agx Xavier And The New Era Of Autonomous Machines
Phoronix Nvidia Jetson Agx Xavier Benchmarks Incredible Performance On The Edge Image Jetson Xavier 3
Nvidia Jetson Agx Xavier Benchmarks Incredible Performance On The Edge Review Phoronix

Nvidia Xavier Shatters Records Excels In Back To Back Performance Benchmarks Self Driving Cars 360

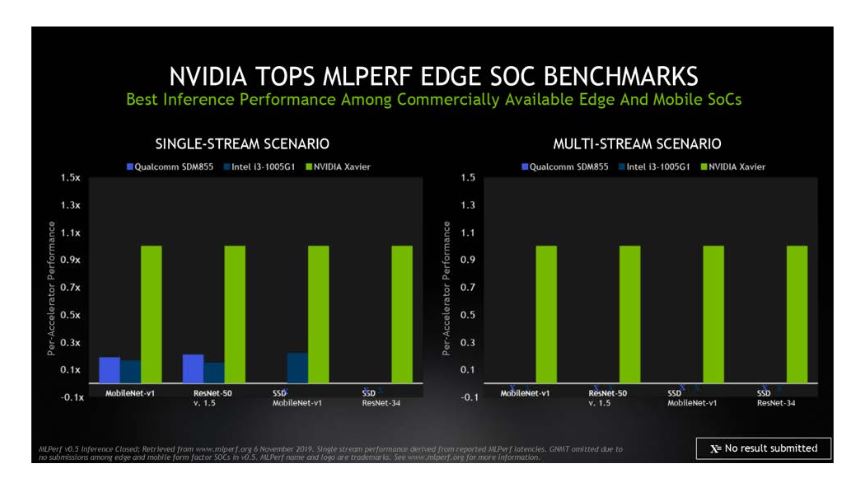
Nvidia Tops Mlperf Ai Inference Benchmarks Insidehpc
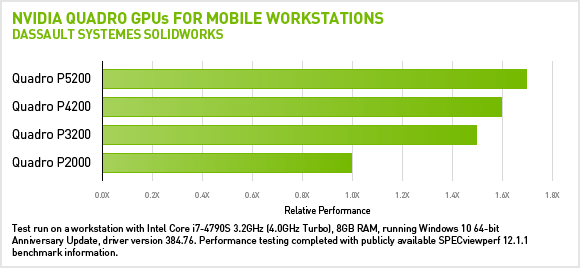
Latest Solidworks Performance Benchmarks Nvidia Quadro Nvidia

Nvidia S Ai Is Leading Industry More Gpus Than Cpus Ie

Nvidia Tops Ai Inference Benchmarks Also Announces World S Smallest Supercomputer Chip For Ai Tasks Forbes India


