Nvidia A100 V100

Nvidia Unveils Beastly Tesla V100 Powered By Volta Gpu With 5120 Cuda Cores And 16gb Hbm2 Nvidia Tesla Cuda

Nvidia A100 Gpu Benchmarks For Deep Learning

Enables The World S Largest Gpu Nvidia Deep Learning Terabyte

Nvidia Previews Ampere Architecture With A100 Data Center Graphics Card

Nvidia S New Ampere A100 54 Billion Transistor Gpu Will Revolutionize Data Center Design Hardwarezone Com Sg

Vicor Powering Nvidia S New A100 Tensor Core Gpu Nasdaq Vicr Seeking Alpha

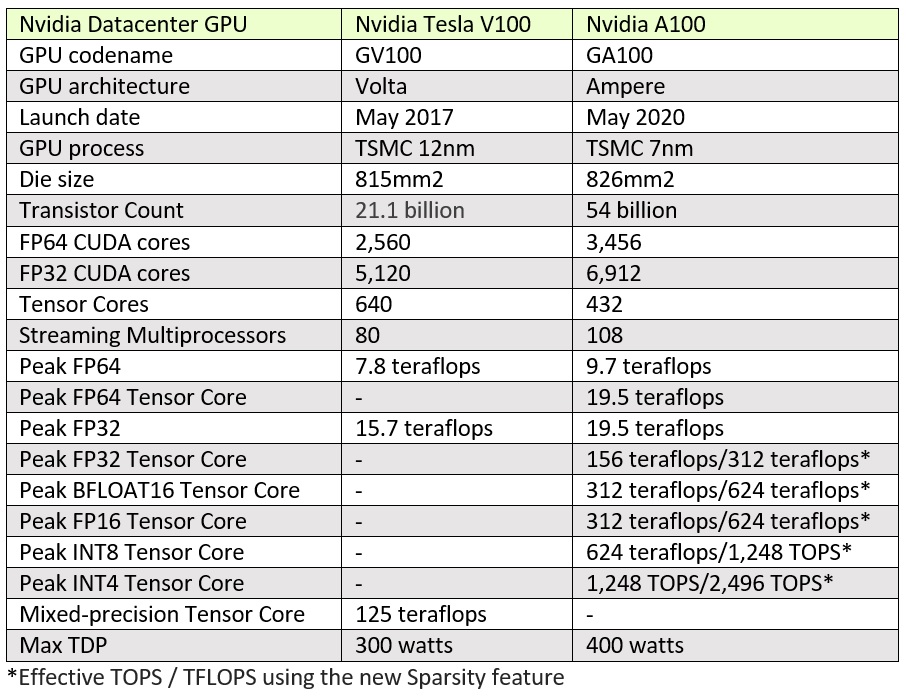
Its die size is 826 square millimeters which is larger than both the v100 815mm2 and.
Nvidia a100 v100. Nvidia tesla a100 v. The new 4u gpu system features the nvidia hgx a100 8 gpu baseboard up to six nvme u 2 and two nvme m 2 10 pci e 4 0 x16 i o with supermicro s unique aiom support invigorating the 8 gpu communication and data flow between systems through the latest technology stacks. Lambda customers are starting to ask about the new nvidia a100 gpu and our hyperplane a100 server. Ideal for large scale deep learning training and neural network model applications.
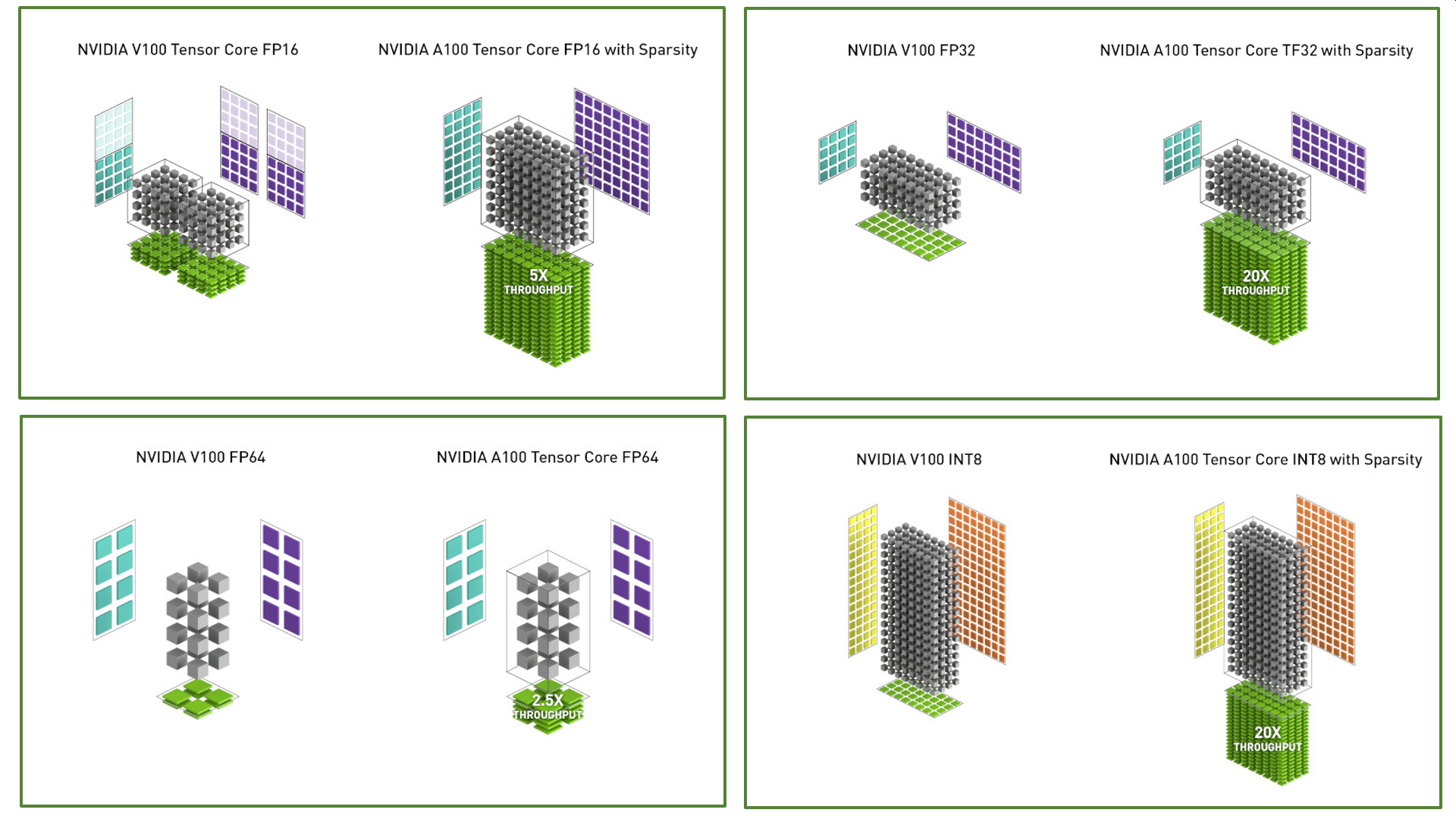
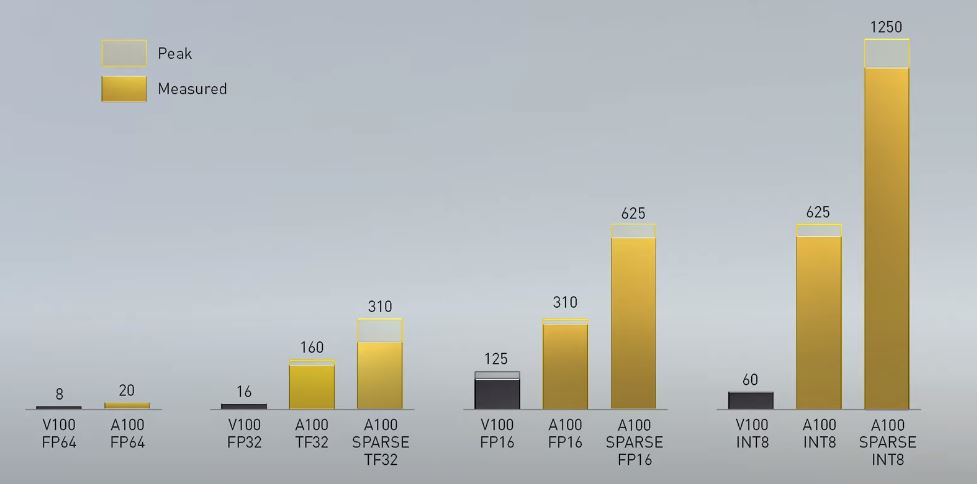
Get the best of sth delivered weekly to your inbox. A100 introduce tensor core a doppia precisione offrendo la principale innovazione dall introduzione del calcolo con gpu a precisione doppia per l hpc. Nvidia accelerator specification comparison. The a100 will likely see the large gains on models like gpt 2 gpt 3 and bert using fp16 tensor cores.
A100 introduces double precision tensor cores providing the biggest milestone since the introduction of double precision computing in gpus for hpc. Nvidia was a little hazy on the finer details of ampere but what we do know is that the a100 gpu is huge. Questo permette ai ricercatori di ridurre i tempi di simulazione pari a circa 10 ore in precisione doppia su gpu nvidia v100 tensor core a sole poche ore su a100. For language model training we expect the a100 to be approximately 1 95x to 2 5x faster than the v100 when using fp16 tensor cores.
Nvidia s current gen tesla v100 comes with 16gb and 32gb hbm2 options while the v100 was built on the 12nm node at tsmc it packs just 21 billion transistors in comparison. 4u system with hgx a100 8 gpu. Nvidia ampere a100 gpu breaks 16 ai world records up to 4 2x faster than volta v100 the results come in from mlperf which is an industry benchmarking group formed back in 2018 with a focus purely. A100 pcie a100 sxm4 v100 pcie p100 pcie fp32 cuda cores.
By opting in you agree to have us send you our newsletter.
Nvidia Quietly Adds Experimental Multi Gpu Rendering Mode To Its Geforce Drivers Nvidia Rendering Multi
Nvidia Ampere Architecture In Depth Nvidia Developer Blog
Nvidia Launches Ampere Gpu With Up To 20x The Ai Performance

Nvidia A100 Ampere Benchmarked The Fastest Gpu Ever Recorded Videocardz Com

Nvidia Dgx A100 Powered By Up To 16x Next Gen Ampere Ga100 Gpus Tweaktown

Nvidia T4 Tensor Core Gpu For Ai Inference Nvidia Data Center

Http Dellemcstudy Blogspot Com 2020 09 Benchmarking Machine Learning Html In 2020 Machine Learning Machine Learning Models Deep Learning

Nvidia S Tesla A100 Has A Whopping 6 912 Cuda Cores Specs Detailed Oc3d News

Tesla Latest Articles And Reviews On Anandtech

Nvidia Quietly Adds Experimental Multi Gpu Rendering Mode To Its Geforce Drivers Nvidia Rendering Multi
Nvidia A100 Ampere Resets The Entire Ai Industry Servethehome

Nvidia S 5 Biggest Gtc 2020 Announcements From A100 To Smartnics

Nvidia Quietly Adds Experimental Multi Gpu Rendering Mode To Its Geforce Drivers Nvidia Rendering Multi


