Nvidia A100 Deep Learning Benchmark

Nvidia A100 Gpu Benchmarks For Deep Learning

Nvidia Ampere A100 Is The Fastest Ai Gpu 4 2x Faster Than Volta V100

Titan V Deep Learning Benchmarks With Tensorflow In 2019

Nvidia New A100 Ampere Gpu Dlbt Deep Learning Benchmark Tool By Techno Premium Medium
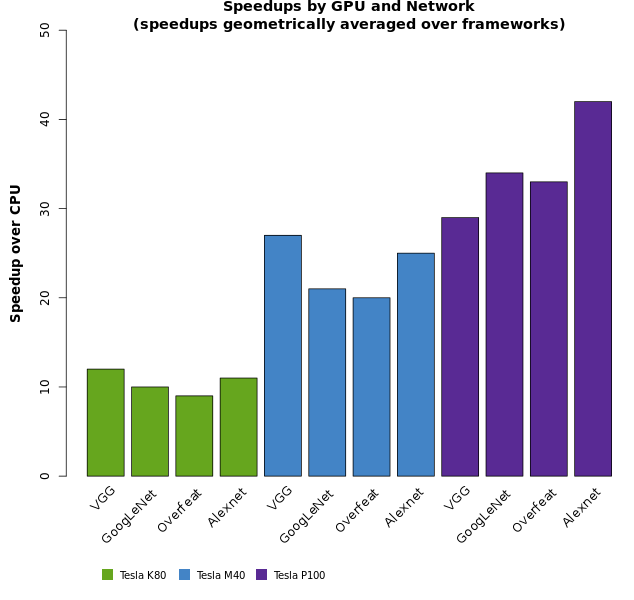
Deep Learning Benchmarks Of Nvidia Tesla P100 Pcie Tesla K80 And Tesla M40 Gpus Microway

Tensorflow Benchmarks For Exxact Server Featuring Nvidia V100s
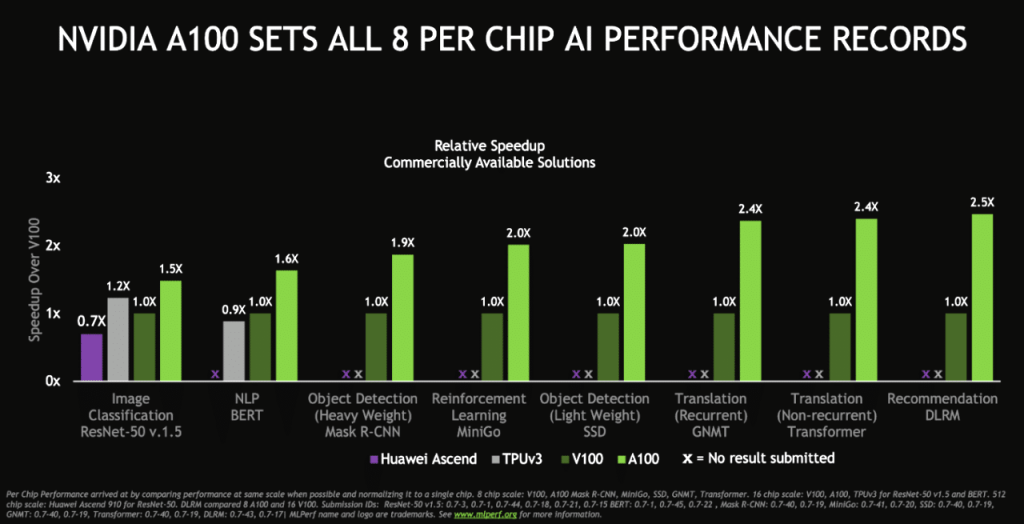
Nvidia a100 tensor core gpus provides unprecedented acceleration at every scale setting records in mlperf the ai industry s leading benchmark and a testament to our accelerated platform approach.
Nvidia a100 deep learning benchmark. This page gives a few broad recommendations that apply for most deep learning operations and links to the other guides in the documentation with a short explanation of their content and how these pages fit together. Conclusion in this blog we quantified the mlperf inference v0 7 performance on dell emc dss8440 and poweredge r7525 severs with nvidia a100 rtx8000 and t4 gpus with resnet50 ssd w resnet34 dlrm bert rnn t and 3d unet benchmarks. Lambda customers are starting to ask about the new nvidia a100 gpu and our hyperplane a100 server. The a100 will likely see the large gains on models like gpt 2 gpt 3 and bert using fp16 tensor cores.
The t4 cards yield the lowest performance. As the engine of the nvidia data center platform a100 can efficiently scale to thousands of gpus or with nvidia multi instance gpu mig technology be partitioned into seven gpu instances to. The a100 tensor core gpu demonstrated the fastest performance per accelerator on all eight mlperf benchmarks. He works with customers and partners to bring the world s highest performance server platform for ai deep learning and hpc to market.
Getting started with deep learning performance this is the landing page for our deep learning performance documentation. The following benchmark includes not only the tesla a100 vs tesla v100 benchmarks but i build a model that fits those data and four different benchmarks based on the titan v titan rtx rtx 2080 ti and rtx 2080 1 2 3 4 in an update i also factored in the recently discovered performance degradation in rtx 30 series gpus. Tensor cores are the center of deep learning we use fp32 and fp16 when training the models even with the new mixed presicion fp16 most developers still using fp32 and thats why nvidia focus on this when releasing this new gpu and they add a new ft32 that its up to 20x faster than fp32 to have an idea of the performance check the picture below. Nvidia s complete solution stack from gpus to libraries and containers on nvidia gpu cloud ngc allows data scientists to quickly get up and running with deep learning.
A100 amber benchmark cloudera cluster containerization coprocessor cpu cryoem cuda data analytics deep learning dgx education gk210 gpu gromacs grub guide hadoop high performance computing hoomd blue hpc k80 linux kernel m40 matlab mdadm memory namd nvidia digits nvlink openacc openmp openpower p40 p100 phi raid sc conference tesla test drive v100. He co authored the initial pci express industry standard specification and is a co inventor of 12 patents. The nvidia a100 tensor core gpu delivers unprecedented acceleration at every scale for ai data analytics and high performance computing hpc to tackle the world s toughest computing challenges. William originally joined nvidia as a graphics processor chip designer.
For overall fastest time to solution at scale the dgx superpod system a massive cluster of dgx a100 systems connected with hdr.

Hgx 2 Benchmarks For Deep Learning In Tensorflow 16x V100 Exxact

Nvidia Ampere Architecture In Depth Nvidia Developer Blog

Nvidia And Google Claim Bragging Rights In Mlperf Benchmarks As Ai Computers Get Bigger And Bigger Mc Ai

Quadro Rtx 8000 Benchmarks For Deep Learning In Tensorflow 2019

Nvidia Quadro Rtx 6000 Gpu Performance Benchmarks For Tensorflow Exxact

Deep Learning Benchmarks Comparison 2019 Rtx 2080 Ti Vs Titan Rtx Vs Rtx 6000 Vs Rtx 8000 Selecting The Right Gpu For Your Needs Exxact

Titan Rtx Benchmarks For Deep Learning In Tensorflow 2019 Xla Fp16 Fp32 Nvlink Exxact

Http Dellemcstudy Blogspot Com 2020 09 Benchmarking Machine Learning Html In 2020 Machine Learning Machine Learning Models Deep Learning

Nvidia Merlin Powers Fastest Commercially Available Solution For Recommender Systems Training Nvidia Developer News Center

Pin On 24 7 Web Zoo Com
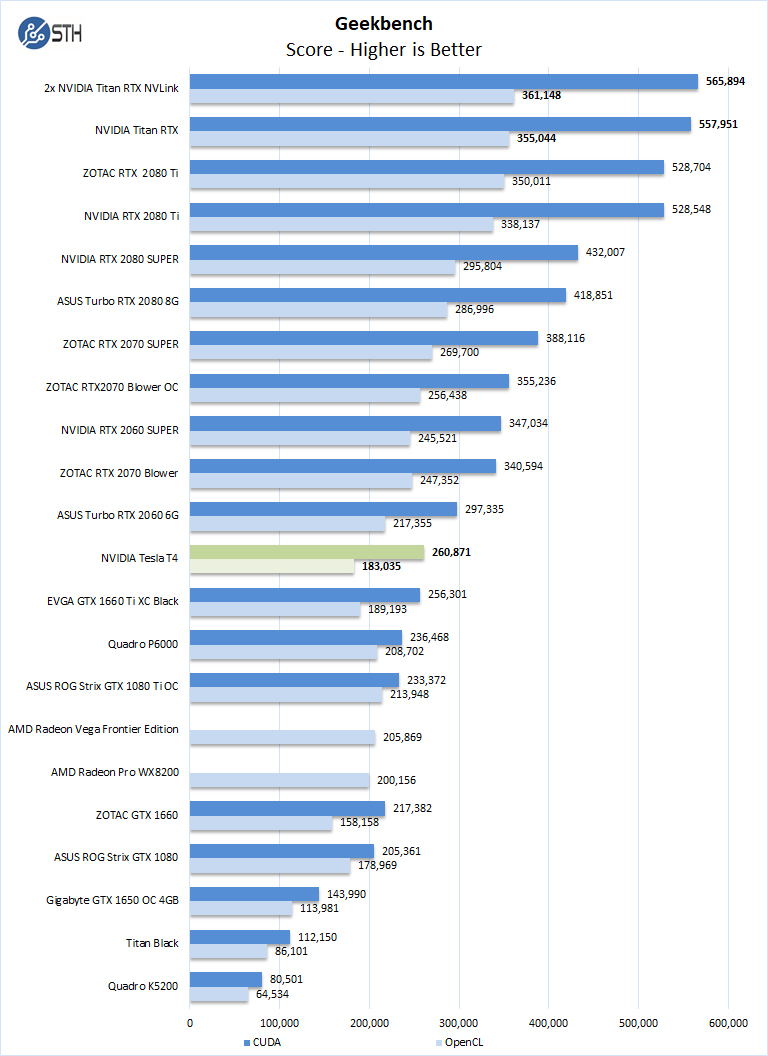
Nvidia Tesla T4 Ai Inferencing Gpu Benchmarks And Review Page 3 Of 5 Servethehome

Computer Makers Unveil 50 Ai Servers With Nvidia S A100 Gpus Artificialintelligence Ai Machinelearning In 2020 Deep Learning Structure And Function Nvidia

Pin On Latest Technology News