Nvidia A100 Bert

Nvidia Ampere Architecture In Depth Nvidia Developer Blog

Defining Ai Innovation With Nvidia Dgx A100 Nvidia Developer Blog

Nvidia A100 Gpu Benchmarks For Deep Learning
State Of The Art Language Modeling Using Megatron On The Nvidia A100 Gpu Nvidia Developer Blog

Nvidia Ampere A100 Is The Fastest Ai Gpu 4 2x Faster Than Volta V100

Experience The Powerful Nvidia Pascal Architecture
Empirical performance is another.
Nvidia a100 bert. 3 v100 used is single v100 sxm2. A100 gpu hpc application speedups compared to nvidia tesla v100. Trt 7 1 precision fp16 batch size 256 a100 with 7 mig instances of 1g 5gb. Lambda customers are starting to ask about the new nvidia a100 gpu and our hyperplane a100 server.
Framework network throughput gpu server container precision batch size dataset gpu version. Insieme a nvidia nvlink di terza generazione nvidia nvswitch pci gen4 mellanox infiniband e il software sdk nvidia magnum io è possibile scalare fino a migliaia di gpu a100. State of the art language modeling using megatron on the nvidia a100 gpu. Nvidia tensorrt trt 7 1 precision int8 batch size 256 v100.
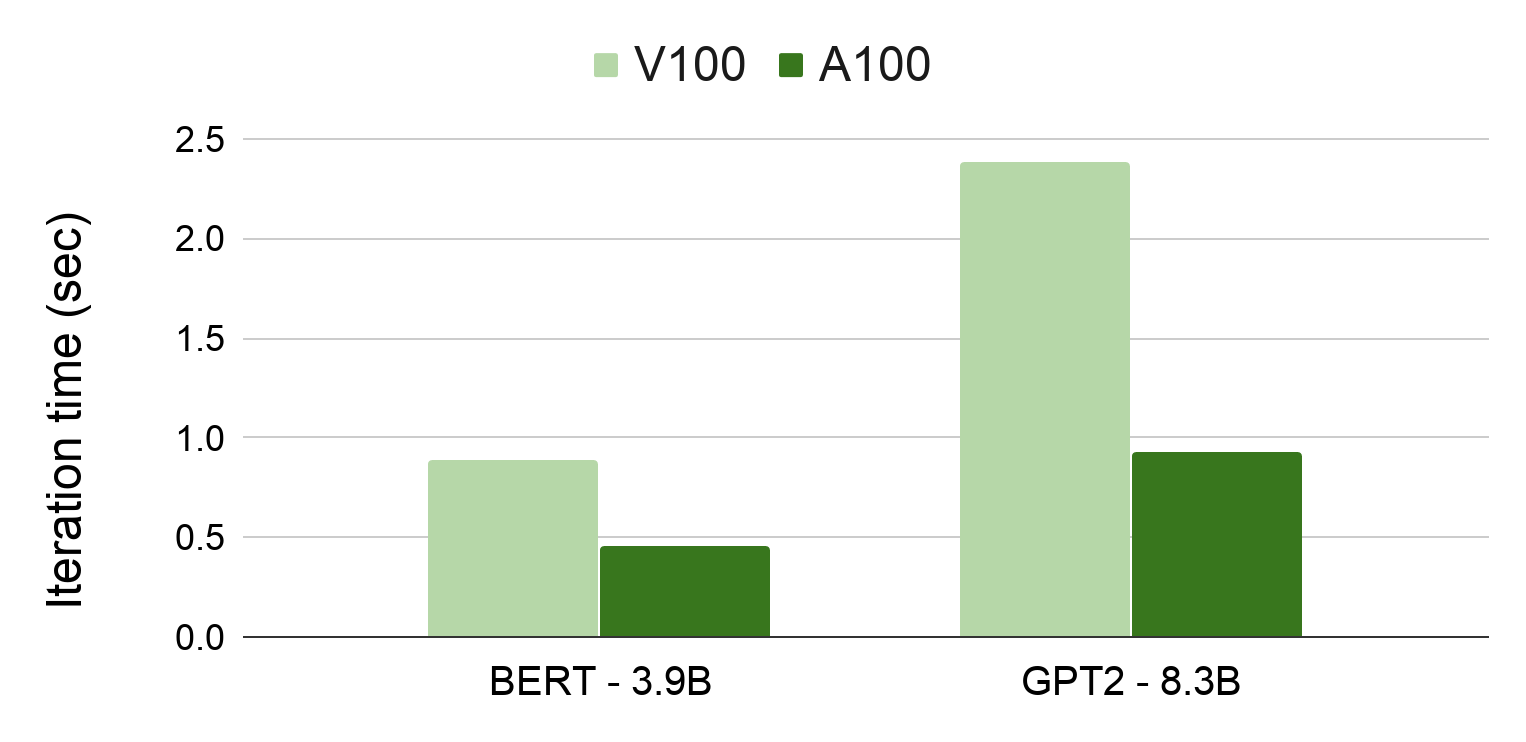
The a100 will likely see the large gains on models like gpt 2 gpt 3 and bert using fp16 tensor cores. A100 used is single a100 sxm4. Questo significa che i modelli ia voluminosi come bert possono essere addestrati in soli xx minuti su un cluster di xx a100 offrendo prestazioni e scalabilità senza precedenti. Specifications are one thing.
For language model training we expect the a100 to be approximately 1 95x to 2 5x faster than the v100 when using fp16 tensor cores. To benchmark and compare the v100 to the a100 test followed nvidia s deep learning examples library. Unified ai acceleration for bert large training and inference. Nvidia a100 bert training benchmarks.
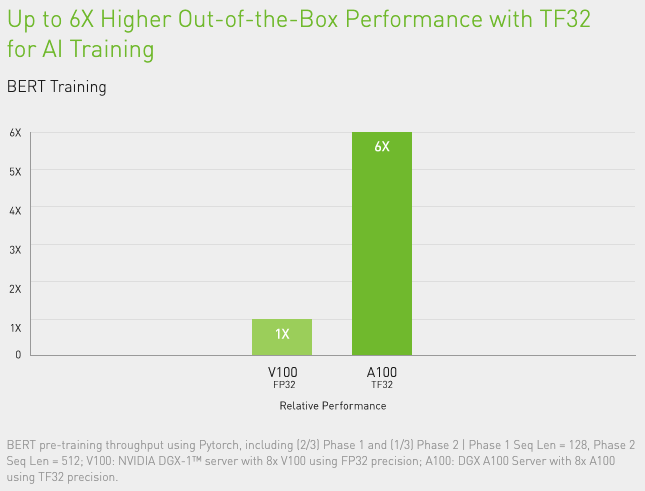
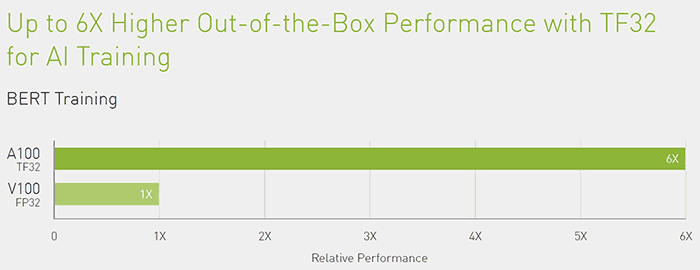
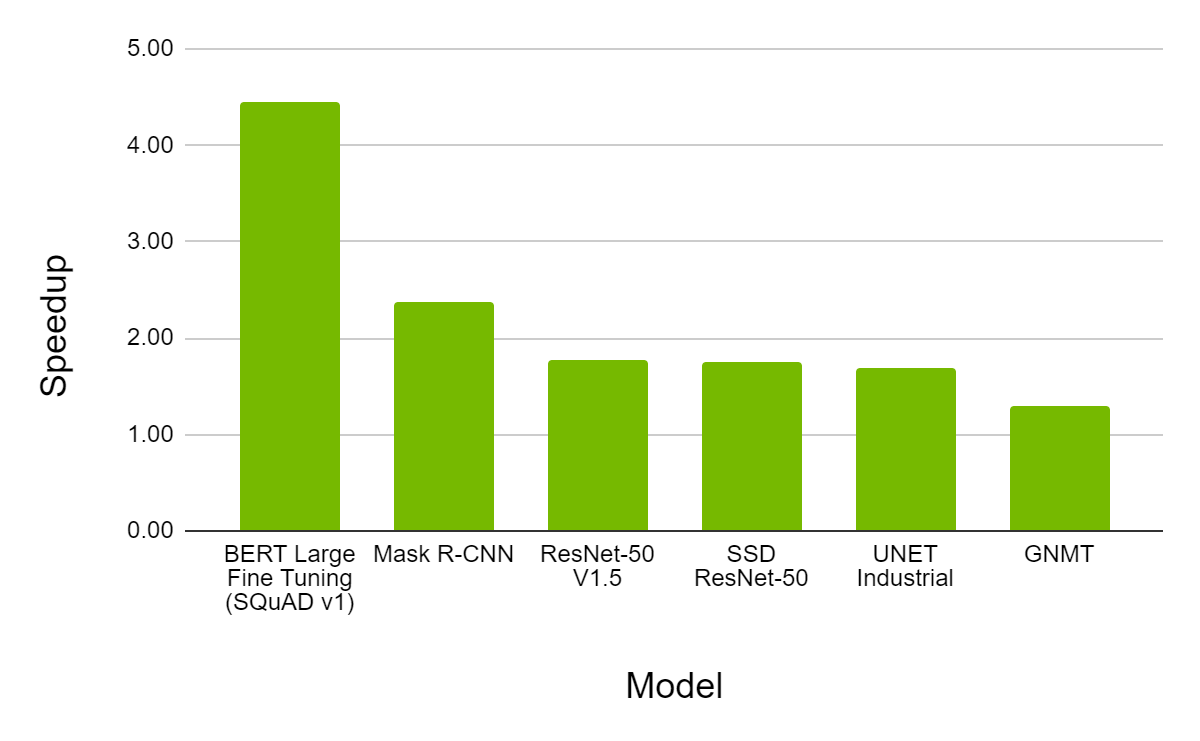
Using sparsity an a100 gpu can run bert bidirectional encoder representations from transformers the state of the art model for natural language processing 50 faster than with dense math. Ai deep learning. The nvidia a100 tensor core gpu delivers unprecedented acceleration at every scale for ai data analytics and high performance computing hpc to tackle the world s toughest computing challenges. The workloads tested were bert large for language modeling jasper for speech recognition maskrcnn for image segmentation and gnmt for translation.
Nvidia a100 gpu on new sxm4 module. As the engine of the nvidia data center platform a100 can efficiently scale to thousands of gpus or with nvidia multi instance gpu mig technology be partitioned into seven gpu instances. Pre production trt batch size 94 precision int8 with sparsity. By mohammad shoeybi mostofa patwary raul puri patrick legresley jared casper and bryan catanzaro may 14 2020.
A100 is part of the complete nvidia data center solution that incorporates building blocks across hardware networking software libraries and optimized ai models and applications from ngc representing the most powerful end to end ai and hpc platform for data centers it allows researchers to deliver real world results and deploy solutions into production at scale.
System Makers Take The Wraps Off Their Nvidia A100 Gpu Servers Graphics News Hexus Net

Nvidia A100 Tensor Core Gpu Dgx A100 Revealed In Ampere Debut
Accelerating Tensorflow On Nvidia A100 Gpus Edge Ai And Vision Alliance

Multimodal Conversational Ai Platform Nvidia

How To Get The Bert Inference Performance On A100 Issue 796 Nvidia Tensorrt Github
Https Developer Download Nvidia Com Video Gputechconf Gtc 2020 Presentations S21730 Inside The Nvidia Ampere Architecture Pdf
Https Www Nvidia Com Content Dam En Zz Solutions Data Center Dgx A100 Dgxa100 System Architecture White Paper Pdf
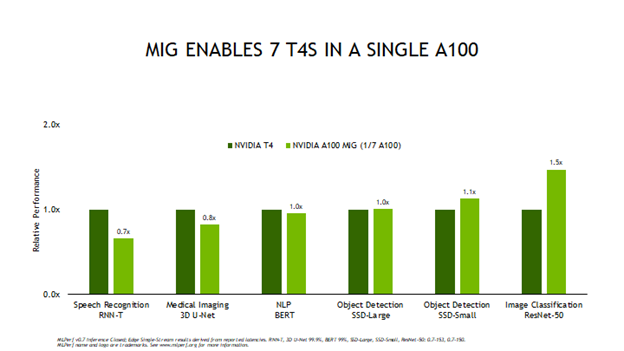
Winning Mlperf Inference 0 7 With A Full Stack Approach Nvidia Developer Blog

Nvidia S Ampere Gpus Come To Google Cloud
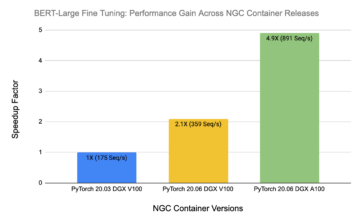
Tag Bert Nvidia Developer Blog
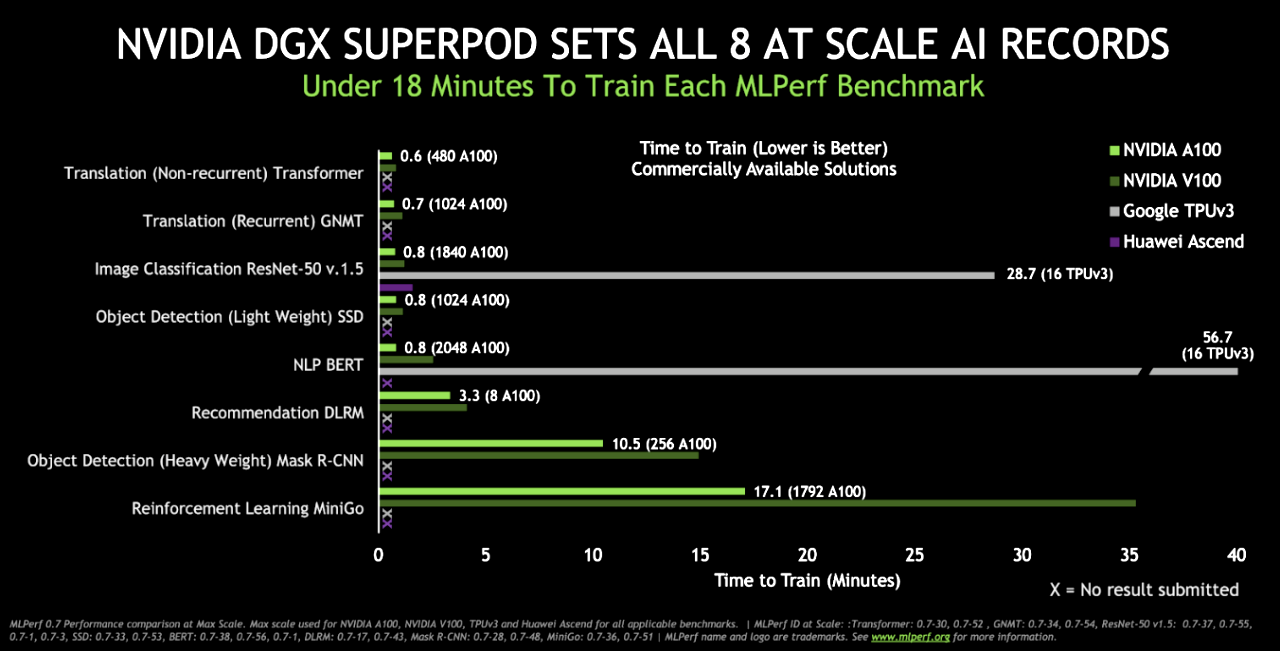
Nvidia Breaks 16 Records In Mlperf Ai Benchmarks Ten15am

Nvidia S Dgx A100 Unprecedented Performance Groupware Technology


